-
[OS] Swap Space와 Page Fault: 메모리 부족을 해결하는 운영체제의 방식CS/OS 2025. 10. 17. 19:14
현실: 모든 프로세스를 다 메모리에 담을 수 없다
지금까지 우리는 "프로세스의 전체 주소 공간이 메모리에 올라가 있다"고 가정해왔다.
하지만 현실은 다르다. 수많은 프로그램이 동시에 실행되고, 각 프로그램은 수백MB~GB를 요구한다. 물리메모리(RAM)은 한정돼 있고, 동시에 수많은 프로세스가 실행되고 있다. 이때 운영체제는 어떻게 모든 프로세스가 문제없이 돌아가도록 할까?
해결책은 물리 메모리의 다른 레벨 계층을 사용하는 것이다.
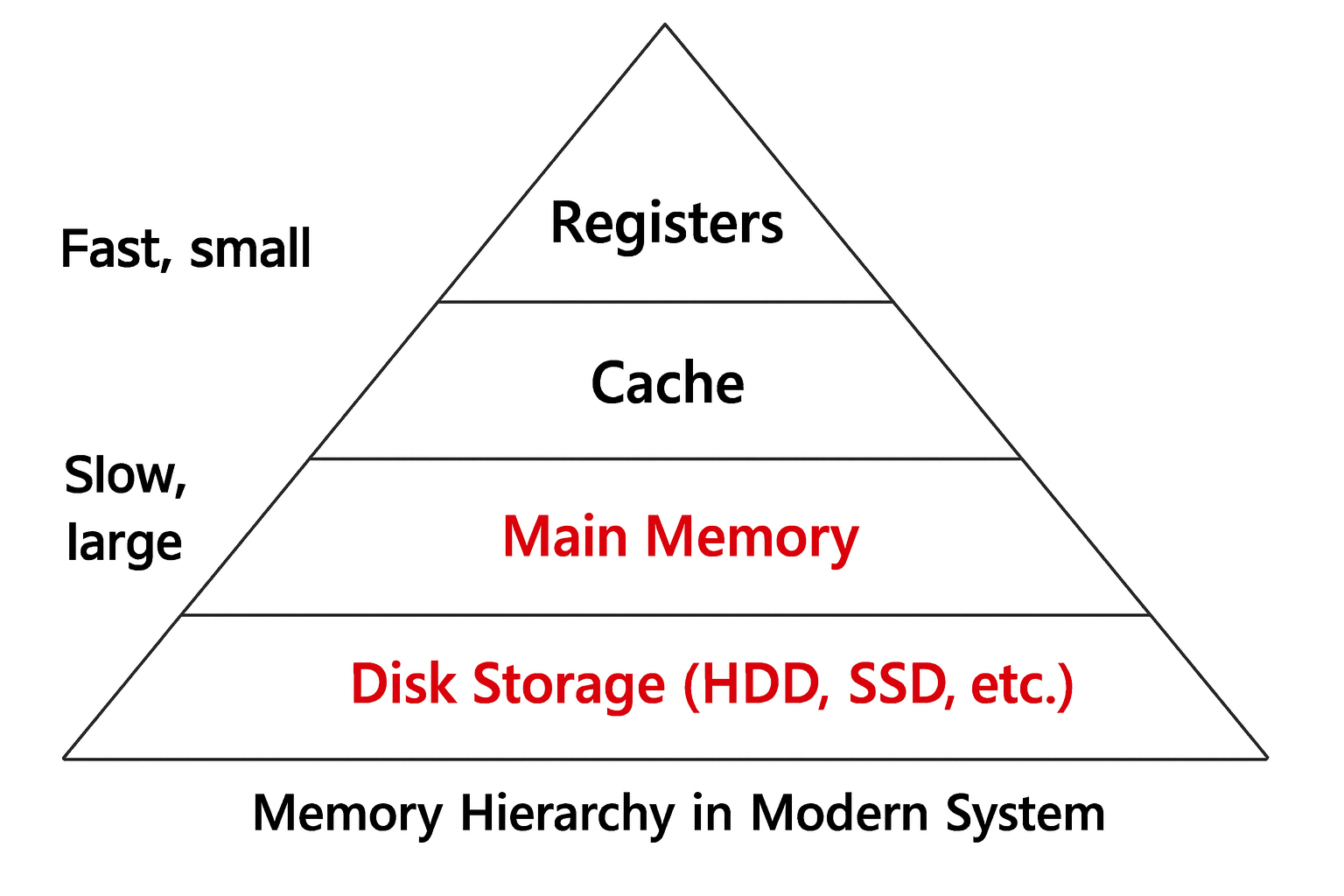
즉, 여기선 Disk 영역을 사용하는 것이다.
- Main memory: 빠르지만 작다.
- Disk: 느리지만 크다.
이렇게까지해서 큰 가상 메모리를 지원하는 이유가 뭘까?
- Convenience for programmers:
- 개발자는 메모리 사이즈를 걱정하지 않고, 단지 할당하면 됨
- Multiprogramming needs it too:
- 다중 프로세스가 한 번에 물리 메모리에 맞지 못하는데, Swap space는 큰 가상 메모리가 다중 프로세스가 접근하는 것을 허용한다.
Swap Space와 Page Fault: 물리 메모리를 넘어서
RAM은 한정돼 있고, 동시에 수많은 프로세스가 실행되고 있다. 이런 상황에서 운영체제는 어떻게 모든 프로그램이 끊김 없이 동작하게 만들까? 그 해답이 바로 Swap Space 와 Page Fault 이다.
Swap Space: 메모리의 임시 보관함
운영체제는 디스크의 일부를 Swap Space(스왑 공간) 으로 예약해 둔다. 이 공간은 말 그대로 메모리에서 잠시 퇴출된 페이지들을 보관하는 창고다.
"RAM이 꽉 찼으니까, 이 페이지는 잠시 디스크에 맡겨둘게" 라는 식이다.
Swap 동작 방식
- 메모리가 부족해지면 OS는 자주 사용하지 않는 페이지를 디스크로 내보낸다.
- 이때 단위는 페이지(Page)단위이다(보통 4KB나 8KB).
- 나중에 그 페이지가 다시 필요해지면, OS가 다시 디스크에서 읽어온다.
즉, 운영체제는 메모리와 디스크를 오가며 페이지를 swap한다.

운영체제가 페이지를 디스크로 내보낼 때, 그 모든 페이지를 Swap Space로 보내는 건 아니다. 페이지의 Source에 따라 다르게 처리한다.
이제 하드웨어가 실제로 어떤 기준으로 페이지를 찾는지 보자.
Present Bit: 페이지가 물리메모리에 있나?
CPU가 메모리에 접근할 때, 하드웨어(MMU)는 페이지 테이블(Page Table) 을 보고 그 페이지가 실제 메모리에 있는지를 확인한다.
이때 쓰이는 게 바로 Present Bit 이다.
비트 의미 1 페이지가 실제 메모리에 있음 0 페이지가 디스크(스왑)에 있음 CPU는 Present Bit = 0 인 페이지를 접근하려 하면 Page Fault(페이지 폴트) 예외를 일으킨다.
즉, OS에게 이 페이지는 지금 메모리에 없으니 가져와달라는 신호이다.
Handling Page Faults: 페이지 폴트는 항상 OS가 처리한다
CPU가 가상 주소로 메모리에 접근했는데, 해당 페이지가 RAM에 없으면 페이지 폴트(Page Fault) 가 발생한다.
TLB가 하드웨어/소프트웨어 어느 쪽에서 관리되든, 폴트 처리는 항상 운영체제(커널)의 책임이다.
- 폴트가 발생하면 커널의 page fault handler가 실행된다.
- 페이지가 스왑으로 나가 있었다면, OS는 디스크에서 해당 페이지를 읽어와 RAM에 올린 뒤 다시 명령을 재실행시킨다.
- 어디서 읽어와야 하는지(스왑 공간, 실행 파일)에 대한 단서(디스크 위치/출처) 는 보통 PTE(Page Table Entry) 에 저장된다.
Handling Page Faults 과정
Page fault가 실제로 처리되는 과정을 한 바퀴 돌려 보면 이렇다.
- PTE에서 디스크 위치 확인
- 디스크 I/O 발행(해당 페이지 읽어오기)
- I/O 동안 해당 프로세스는 Blocked 상태
- I/O 완료 후 페이지 테이블 갱신(이제 Present=1, PFN 기록)
- 문제의 명령 재시도 → 이때 TLB 미스가 날 수 있음
- TLB 업데이트(새 변환 결과 채움)
- 명령 정상 실행(이번엔 TLB 히트)
즉, CPU 입장에선 두 번째 시도에 성공한 것처럼 보이지만, 그 사이에 OS가 페이지를 가져오고 메타데이터를 정리해 둔 것이다.
메모리가 모두 찼다면? : Page Replacement
RAM이 이미 가득 차 있는데 새 페이지를 올려야 한다면, 누군가는 나가야 한다. 이때 누구를 내보낼지 정하는 게 Page Replacement policy이다.
왜 중요할까?
- 잘못 고르면 디스크 왕복이 증가 → 프로그램이 사실상 디스크 속도로 굴러감(수천~수만 배 느림).
- 좋은 교체 정책은 시스템 전체 효율을 좌우한다.
Page Replacement Policy에 대해서는 다음에 포스팅 하도록 하겠다.
Page Fault Control Flow
큰 흐름은 단순하다.

접근 → (TLB 확인 → 필요 시 PTE 확인) → Present=0이면 폴트 → OS가 디스크에서 읽어 RAM에 적재 → PTE/TLB 갱신 → 명령 재시도
이제 하드웨어·소프트웨어 관점으로 쪼개서 보자.
Hardware-side Flow
CPU가 가상 주소를 해석할 때 먼저 TLB를 확인하고, 없으면 페이지 테이블을 본다.

접근 권한과 Present 비트를 체크해 물리메모리에 없고 디스크에 있으면 Page fault를 일으킨다.
Software-side Flow
이제 운영체제가 개입한다. 커널의 Page Fault Handler가 빈 프레임 확보 → 디스크에서 읽기 → PTE 갱신 → 명령 재시도의 과정을 수행한다.

- 빈 프레임이 없으면 교체 알고리즘을 통해 페이지를 내보내야한다.
- 디스크 I/O는 느리므로 해당 프로세스는 대기(블록)한다.
- 완료 후에는 PTE 업데이트 → 재실행.
그러면 언제 Page 교체를 할까?
교체는 "그때그때"만 하는 게 아니라 watermarks(임계치) 로 관리한다.
- Low Watermark(LW) 이하로 free page가 줄면 백그라운드 스레드(= swap/page daemon) 가 동작 시작.
- High Watermark(HW) 이상이 될 때까지 여러 페이지를 한 번에 비워낸다(클러스터링/배치 I/O로 효율 증가).
- 덕분에 포그라운드 폴트 처리의 지연을 줄이고, 일괄 I/O 로 디스크 효율을 높인다.
아래는 Linux의 예시이며, 여기서 swap daemon은 kswapd이다.

정리
- 가상 메모리는 RAM을 디스크까지 확장해 "큰 주소 공간"이라는 환상을 제공한다.
- Present Bit가 0이면 페이지 폴트 → OS가 디스크에서 페이지를 가져와 PTE/TLB를 갱신하고 명령을 재시도한다.
- RAM이 꽉 찼다면 페이지 교체 정책으로 내보낼 페이지를 고른다. watermarks와 swap daemon으로 안정적인 여유 프레임을 유지한다.
- 코드 페이지(파일 기반) 는 스왑을 쓰지 않고 원본 파일에서 재로딩하는 최적화가 가능하다.
용어
- Page Fault: RAM에 없는 페이지 접근 시 발생. OS가 디스크에서 가져온다.
- Page Replacement: RAM이 꽉 찼을 때 쫓아낼 페이지를 고르는 정책/메커니즘.
- Transparency: 프로세스는 연속된 큰 주소 공간을 있는 그대로 누리는 착시를 얻고, 뒤에서는 OS가 분산/스왑을 조율한다.
- Cost: 디스크 I/O는 비싸다. Fault가 잦아지면 성능 저하된다.
출처: 경북대학교 한명균 교수님, “운영체제” 강의 자료
'CS > OS' 카테고리의 다른 글
[OS] 운영체제 메모리 관리: Free-Space Management (0) 2025.11.17 [OS] Page Replacement: FIFO, LRU, Clock, 그리고 Thrashing (0) 2025.10.24 [OS] 페이지 테이블의 공간 효율화 단계: Multi-level과 Inverted Page Table (0) 2025.10.17 [OS] Paging을 가속시킨 하드웨어 캐시: TLB (0) 2025.10.14 [OS] 외부 단편화를 해결한 Paging: 등장 배경과 한계 (1) 2025.10.10