-
[Software Engineering] 소프트웨어 개발 생명주기(SDLC)와 프로세스 모델CS/Software Engineering 2026. 4. 14. 20:29
좋은 소프트웨어를 만들겠다고 결심했다. 그런데 막상 팀을 꾸리고 나면 바로 이 질문과 마주친다.
그래서 어떻게 만들 건데?
단순히 코드를 잘 짜는 것만으로는 부족하다. 팀이 어떤 순서로 일하고, 어떤 기준으로 판단하며, 언제 다음 단계로 넘어갈지를 합의하지 않으면 프로젝트는 결국 방향을 잃는다.
이 문제를 해결하기 위해 소프트웨어 공학에서는 소프트웨어 개발 생명주기(SDLC, Software Development Life Cycle) 라는 개념을 정립했고, 이를 구체적으로 운영하는 방식을 프로세스 모델이라고 부른다.
이 글에서는 SDLC의 각 단계가 왜 존재하는지, 그리고 대표적인 프로세스 모델들이 서로 어떻게 다른지를 꼼꼼하게 짚어본다.
SDLC란 무엇인가
소프트웨어 개발을 체계적으로 접근하는 방법은 크게 두 단계의 사고로 나눌 수 있다. (2-tier approach)
- 개발 과정을 의미 있는 단계(stage)로 나눈다. 각 단계는 서로 다른 질문을 던지고, 서로 다른 결과물을 만들어낸다.
- 그 단계들을 논리적인 순서로 연결한다. 무엇이 무엇보다 먼저 와야 하는지를 정의하는 것이다.
이렇게 정의된 전체 흐름이 바로 SDLC다. 소프트웨어 공학에서 합의된 주요 단계는 다음과 같다.
- 계획(Planning) + 요구사항 분석(Requirements Analysis)
- 설계(Design)
- 구현(Implementation)
- 테스팅(Testing / V&V)
- 유지보수(Maintenance)
각 단계를 하나씩 살펴보자
계획(Planning): 이걸 만드는 게 맞는가?
계획 단계의 핵심 질문은 "이 프로젝트를 시작해야 하는가?" 다. 아이디어가 아무리 좋아 보여도, 실현 가능성이 없거나 조직의 역량을 초과하면 시작 자체가 잘못된 것이다.
계획 단계에서 주로 논의하는 내용은 다음과 같다.
- 왜 이 시스템을 만드는가? (사업적 가치)
- 얼마나 걸리는가? 어떤 자원이 필요한가?
- 어떤 리스크가 존재하는가?
- 기술적으로 실현 가능한가? 경제적으로 타당한가? 조직 내에서 실행 가능한가?
이 분석을 타당성 분석(Feasibility Analysis) 이라고 부른다.
기술적(Technical), 경제적(Economic), 조직적(Organisational) 관점 세 가지를 동시에 검토한다.
이 과정을 통해 "진행한다(Go) / 진행하지 않는다(Not Go)" 라는 결정이 내려지면, 그때부터 실질적인 프로젝트 관리가 시작된다. 작업 계획을 수립하고, 팀을 구성하고, 이후 전체 진행 상황을 모니터링하는 작업이 계속 이어진다.
요구사항 분석(Requirements Analysis): 정확히 무엇을 만들 것인가?
계획이 "시작할 것인가?"를 결정한다면, 요구사항 분석은 "그래서 무엇(What)을 만들 것인가?" 를 정의한다. 두 단계는 겹치는 부분도 있지만, 초점이 다르다.
요구사항 분석에서 다루는 질문들은 이렇다.
- 누가 이 시스템을 사용할 것인가?
- 시스템이 어떤 기능을 제공해야 하는가?
- 예외 상황은 어떻게 처리할 것인가?
- 어떤 제약 조건이 존재하는가?
이 단계의 활동은 크게 두 종류로 나뉜다.
인간 중심 활동은 자연어로 진행되며, 태생적으로 모호하다.
- 요구사항 수집(Elicitation): 이해관계자 인터뷰, 워크샵 등을 통해 "사용자가 진짜 원하는 것"을 끌어낸다. 사용자가 원한다고 말하는 것과 실제로 필요한 것은 종종 다르다.
- 타당성 검토 및 협상: 모든 요구사항을 다 구현할 수는 없다. 무엇을 우선할지 합의하는 과정이 필요하다.
형식화 활동(Formalisation activities)은 수집한 요구사항을 엄밀한 형태로 표현하는 작업이다.
- 형식 명세(Formal Specification): 요구사항을 논리/수학적 표기법으로 변환한다. 이를 통해 자동화된 검증(Formal Verification)이 가능해진다.
형식 명세 예시: Linear Temporal Logic (LTL)
LTL은 시간에 따라 변하는 시스템의 동작을 기술하는 데 쓰이는 논리 체계다. 두 가지 핵심 연산자가 있다.
- □P: "P는 항상 참이다"
- ◊Q: "Q는 언젠가는 참이 된다"
예시 1. 교통 신호 제어기 (안전성 속성)
"초록 불은 항상 결국 빨간 불로 바뀌어야 한다. 무한히 초록 불이 켜져 있으면 안 된다."
□ (green → ◊red)이 수식은 "초록 불 상태가 되면, 반드시 언젠가는 빨간 불 상태가 되어야 한다"는 것을 수학적으로 표현한다. 이 성질이 깨지면 차량이 영원히 지나갈 수 없는 상황이 발생한다.
예시 2. 로그인 인증 시스템 (보안 속성)
"로그인 시도가 3회 이상 실패하면, 시스템은 반드시 접근 허가 또는 계정 차단 중 하나를 수행해야 한다."
□ (attempts ≥ 3 → ◊(grant_access ∨ block))이처럼 자연어로 작성한 요구사항은 해석의 여지가 생기지만, LTL로 명세하면 의미가 단 하나로 고정된다. 그리고 이 명세를 바탕으로 시스템이 해당 성질을 만족하는지 자동으로 검증할 수 있다.
설계(Design): "어떻게 만들 것인가?" (청사진)
요구사항이 "무엇을 만들지"를 정의했다면, 설계는 "어떻게 만들지" 를 결정한다. 요구사항 명세(SRS, Software Requirements Specification)를 입력으로 받아, 이를 충족하는 구체적인 시스템 구조를 설계하는 단계다.
설계 단계에서 결정해야 할 주요 사항들은 다음과 같다.
- 시스템 아키텍처: 시스템의 전체 구조는 어떻게 되는가? (모놀리식 vs 마이크로서비스, 클라이언트-서버 구조 등)
- 데이터 모델링: 실세계 데이터를 어떻게 표현하고, 어디에 저장할 것인가?
- 인터페이스 설계: 컴포넌트 간 상호작용은 어떻게 정의할 것인가?
- 컴포넌트 선택: 어떤 기술 스택과 라이브러리를 사용할 것인가?

설계의 결과물은 크게 네 가지다: 시스템 아키텍처 문서, 데이터베이스 설계, 인터페이스 명세, 컴포넌트 설명서. 이를 표현하기 위해 UML(Unified Modeling Language) 같은 시각적 표기법이 널리 쓰인다.
구현(Implementation): "코드를 작성한다"
이 단계는 설계 결과물을 실제 동작하는 코드로 변환하는 과정이다. 많은 개발자에게 가장 친숙하고, 동시에 가장 복잡한 단계다.
구현 단계에서 다루는 주제들은 다음과 같다.
- 프로그래밍 패러다임: 절차적, 객체지향, 함수형 등 어떤 방식으로 코드를 구성할 것인가?
- 개발 환경(IDE): 어떤 도구를 사용할 것인가?
- 코드 어시스턴트: 자동완성, AI 모델 등을 어떻게 활용할 것인가?
- 코드 자동화: 모델 기반 엔지니어링(Model Driven Engineering), No-Code/Low-Code 운동 등
구현이 어려운 이유
이론상으로는 "이런 기능을 만드는 것 자체는 가능하다"는 게 분명한 경우가 대부분이다. 그럼에도 구현이 어려운 이유는 따로 있다.
- 정보 취득의 어려움: 특정 환경에서 특정 방법이 동작하는지 아무도 시도해본 적이 없을 수 있다.
- 가변성(Variability): 동일한 코드라도 환경에 따라 다르게 동작한다.
- 불명확한 명세: 요구사항이 처음부터 잘못 이해되어 있으면, 완벽하게 구현해도 틀린 것을 만들게 된다.
- 시간 압박: 요구사항을 다 이해하기도 전에 코드를 써야 하는 상황이 비일비재하다.
보일러플레이트 코드(Boilerplate Code)
보일러플레이트(Boilerplate) 라는 단어는 원래 신문 인쇄에서 반복적으로 재사용하던 금속판에서 유래했다. 소프트웨어에서는 반복적으로 등장하는 표준적인 코드 패턴을 뜻한다.
잘 쓰면 코드 재사용성을 높이고 표준화를 이끌어낼 수 있다. 반면 남용하면 불필요한 중복이 늘어나고 유지보수 비용이 증가한다.
테스팅(Testing): "제대로 만들었는가?"
테스팅 단계는 흔히 V&V(Validation & Verification) 라는 용어로 표현된다. 두 개념은 비슷해 보이지만 질문 자체가 다르다.
- Validation(검증): "우리가 올바른 제품을 만들고 있는가?" — 고객의 요구사항을 실제로 만족하는지 확인
- Verification(확인): "우리가 제품을 올바르게 만들고 있는가?" — 개발 과정에서 실수가 없었는지 확인
이 두 질문에 답하는 방식도 두 학파로 나뉜다.
- 합리주의자(Rationalists): "특정 오류가 존재하지 않음을 수학적으로 증명했기 때문에 올바르다." → 형식 검증(Formal Verification)
- 경험주의자(Empiricists): "여러 번 실행해봤는데 잘 돌아갔기 때문에 올바르다." → 소프트웨어 테스팅(Software Testing)
실제 현장에서는 두 방법을 상황에 따라 혼용한다. 안전성이 매우 중요한 시스템(항공, 의료 등)에서는 형식 검증이 필수다.
유지보수(Maintenance): "소프트웨어를 계속 살아있게 하려면?"
소프트웨어는 배포 이후에도 계속 관리가 필요하다. 유지보수는 단순히 버그를 고치는 것에 그치지 않는다.
유지보수 활동의 유형은 크게 네 가지다.
수정적(Corrective) 발견된 버그나 오류를 수정 적응적(Adaptive) 환경 변화(OS 업그레이드, 법규 변경 등)에 대응 완전적(Perfective) 성능 향상, 새로운 기능 추가 예방적(Preventive) 미래의 문제를 방지하기 위한 선제적 개선 리팩토링(Refactoring)
리팩토링은 외부 동작은 바꾸지 않으면서 내부 코드 구조를 개선하는 작업이다. 완전적/예방적 유지보수의 일환으로 이루어진다.
코드 스멜(Code Smell)
코드 스멜은 당장 기능이 깨지지는 않지만, 시스템이 점점 복잡해지면서 문제가 생길 것임을 예고하는 안티패턴이다. 대표적인 유형은 다음과 같다.
1. Long Method
하나의 메서드가 너무 많은 책임을 떠안은 경우다. 아래처럼 주문 유효성 검사, 할인 적용, 인보이스 생성, 이메일 발송까지 한 함수가 모두 처리하면 어떻게 될까.
# Bad: 하나의 함수가 모든 걸 다 한다 def process_order(order): if not order.items: raise ValueError("Order must contain items") if order.total_price <= 0: raise ValueError("Order total must be positive") if order.customer.is_premium: order.total_price *= 0.9 if order.total_price > 100: order.total_price -= 10 invoice = f"Invoice for {order.customer.name}\nTotal: ${order.total_price}" email_content = f"{order.customer.name}, your order has been confirmed!" send_email(order.customer.email, email_content) return invoice이 함수는 테스트하기도, 수정하기도 어렵다. 할인 로직만 바꾸고 싶어도 함수 전체를 건드려야 한다. 해결책은 각 책임을 독립된 함수로 분리하는 것이다.
# Good: 책임을 각각의 함수로 분리 def validate_order(order): if not order.items: raise ValueError("Order must contain items") if order.total_price <= 0: raise ValueError("Order total must be positive") def apply_discounts(order): if order.customer.is_premium: order.total_price *= 0.9 if order.total_price > 100: order.total_price -= 10 def generate_invoice(order): return f"Invoice for {order.customer.name}\nTotal: ${order.total_price}" def send_confirmation_email(order): email_content = f"{order.customer.name}, your order has been confirmed!" send_email(order.customer.email, email_content) def process_order(order): validate_order(order) apply_discounts(order) invoice = generate_invoice(order) send_confirmation_email(order) return invoice각 함수가 하나의 일만 한다. 할인 로직을 바꾸려면 apply_discounts만 수정하면 되고, 각 함수를 독립적으로 테스트할 수 있다.
2. God Class
# Bad: 하나의 클래스가 주문, 고객, 결제, 배송, 이메일을 전부 처리 class OrderSystem: def create_order(self, items): ... def validate_customer(self, customer): ... def apply_discount(self, order): ... def process_payment(self, order, card_info): ... def update_inventory(self, items): ... def schedule_delivery(self, order, address): ... def send_confirmation_email(self, order): ... def generate_invoice(self, order): ... def handle_refund(self, order): ...시스템 내 모든 것을 혼자 알고 혼자 처리하려는 클래스다. 마치 전지전능한 신처럼 비대해진다고 해서 God Class라는 이름이 붙었다.
# Good: 책임별로 클래스를 나눈다 class Order: def create(self, items): ... def apply_discount(self): ... class PaymentProcessor: def process(self, order, card_info): ... def refund(self, order): ... class DeliveryService: def schedule(self, order, address): ... class NotificationService: def send_confirmation(self, order): ...각 클래스가 자신의 영역만 담당하므로, 결제 로직이 바뀌어도 배송이나 이메일 코드는 건드릴 필요가 없다.
3. Middle-Man Class (중간자 클래스)
다른 클래스에 모든 작업을 위임하기만 하고 자신은 아무런 로직도 갖지 않는 클래스다.
# Bad: OrderManager는 Order의 메서드를 그대로 넘겨줄 뿐이다 class OrderManager: def __init__(self, order): self.order = order def get_total_price(self): return self.order.get_total_price() # 그냥 위임 def add_item(self, item): return self.order.add_item(item) # 그냥 위임 def remove_item(self, item): return self.order.remove_item(item) # 그냥 위임OrderManager가 Order의 메서드를 그대로 다시 호출하기만 한다면, OrderManager는 존재할 이유가 없다. 이 경우 Order를 직접 사용하면 된다.
# Good: Order를 직접 사용한다 order = Order() order.add_item(item) total = order.get_total_price()중간자 클래스는 처음에는 "추후 확장을 위해" 만들어지는 경우가 많다. 하지만 실제 로직이 추가되지 않는 한, 불필요한 계층이 생길 뿐이다.
버그 트리아지(Bug Triage)
유지보수 단계에서는 새로운 버그 리포트가 끊임없이 들어온다. 모든 버그를 다 고칠 수는 없다. 그래서 트리아지(Triage) 라는 개념이 필요하다. 의료 현장에서 중증도에 따라 치료 우선순위를 정하듯, 소프트웨어에서도 버그의 심각도를 평가하고 수정 우선순위를 결정한다.
다음과 같은 기준으로 판단한다.
- 이 버그는 얼마나 심각한가? (단순 시각적 문제인가, 시스템 전체가 멈추는 문제인가?)
- 누가 이 버그를 고칠 것인가?
- 지금 당장 고칠 필요가 있는가? (수정 자체가 더 위험한 경우도 있다)
프로세스 모델: SDLC 단계들을 어떻게 연결할 것인가?
SDLC의 각 단계가 무엇인지 이해했다면, 이제 이 단계들을 어떤 순서와 방식으로 실행할지를 결정해야 한다. 이것이 프로세스 모델의 역할이다.

단계들 사이의 의존 관계는 대체로 명확하다. 그런데도 다양한 프로세스 모델이 존재하는 이유는 프로젝트의 성격, 팀의 규모, 요구사항의 안정성, 시간 압박에 따라 최선의 접근법이 달라지기 때문이다.
Waterfall Model
1950년대부터 사용된 가장 오래된 모델이다.
요구사항 → 설계 → 구현 → 테스팅 → 유지보수각 단계가 완료된 이후에야 다음 단계로 넘어간다. 선형적이고 단방향이다.
잘 맞는 상황
- 요구사항이 처음부터 명확하고 안정적일 때
- 시간 압박이 없고 단계별 완결이 가능할 때
주요 단점
- 변경에 취약하다. 구현 중반에 요구사항이 바뀌면 앞 단계로 되돌아가기 매우 어렵다.
- 블로킹이 발생한다. 한 단계가 지연되면 이후 모든 단계가 멈춘다.
- 동작하는 소프트웨어가 맨 마지막에야 나온다. 배포 직전까지 고객이 실제 제품을 볼 수 없다.
V-Model
폭포수 모델의 변형이다. 선형 구조는 유지하면서, 개발 단계와 테스팅 단계를 짝짓는(coupling) 방식으로 확장했다.

구현을 중심으로 왼쪽(설계)과 오른쪽(V&V)이 대칭을 이루는 "V" 자 형태를 가진다. 예를 들어, 상위 수준 설계는 시스템 테스트와, 상세 설계는 단위 테스트와 연결된다.
여전히 본질적으로는 선형 모델이지만, 각 설계 단계에 대응하는 검증 활동을 명시적으로 정의했다는 점에서 의미 있는 발전이다.
Incremental Model
폭포수 모델의 경직성을 극복하기 위해 등장했다.
핵심 아이디어는 "분할 정복(Divide and Conquer)" 이다. 전체 프로젝트를 작은 기능 단위로 나누고, 각 단위를 반복(iteration)을 통해 개발한다. 매 반복 종료 시점에 부분적으로 동작하는 소프트웨어가 나온다.

폭포수 모델과 가장 큰 차이는, 완성된 제품이 나올 때까지 기다릴 필요 없이 중간 산출물을 지속적으로 검토하고 피드백을 반영할 수 있다는 점이다.
Spiral Model
Barry Boehm이 1986년에 제안한 모델이다. 반복적(iterative)이지만 점진적(incremental)이지는 않다는 특징이 있다.
각 사이클은 네 단계로 구성된다.
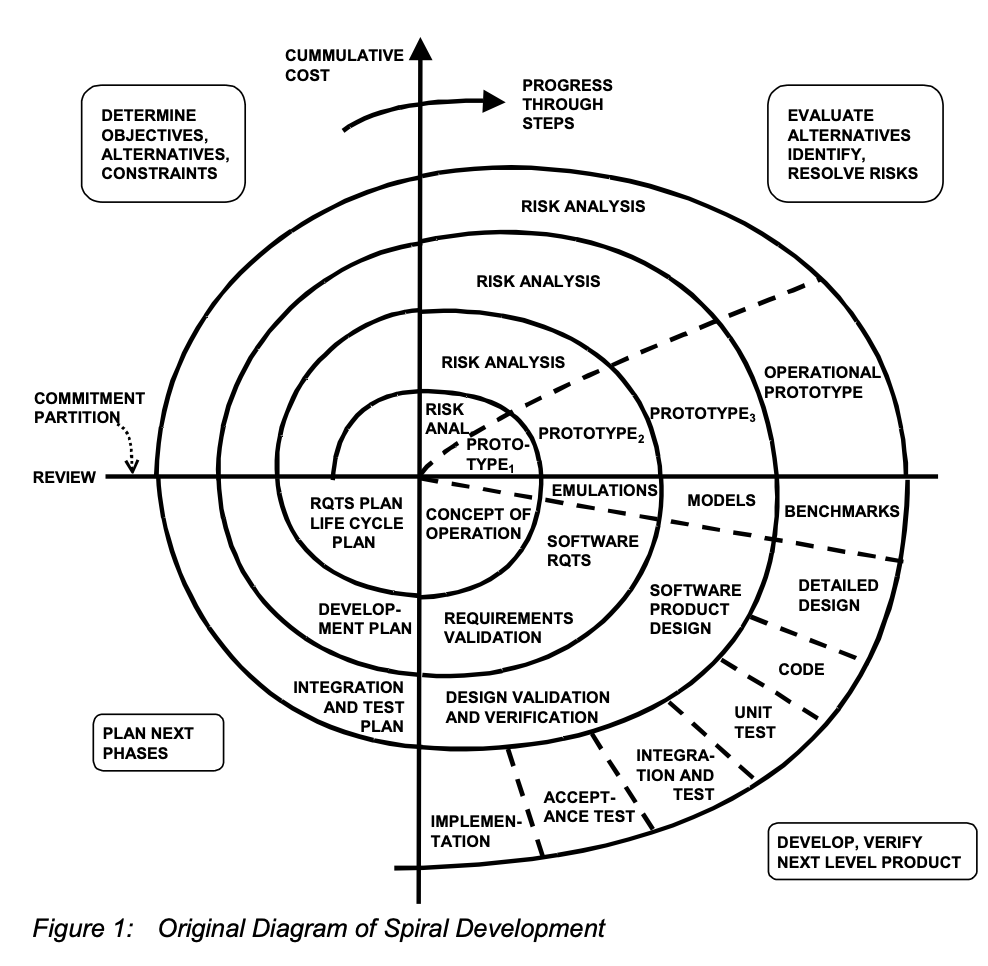
- 목표 결정 (Determine Objectives): 이번 사이클에서 달성할 목표, 대안, 제약 조건을 설정한다.
- 리스크 분석 (Risk Analysis): 발생 가능한 리스크를 식별하고 최소화한다.
- 엔지니어링 (Engineering): 프로토타입 또는 실제 기능을 개발한다.
- 다음 반복 계획 (Plan Next Iteration): 이해관계자 리뷰 후 다음 사이클을 계획한다.
나선형 모델에서 프로토타입은 점진적 모델에서처럼 "부분적으로 완성된 제품"이 아니다.
오히려 불확실한 요구사항을 더 명확하게 만들기 위한 도구다. 이해관계자와 긴밀하게 소통하면서 요구사항을 계속 정제해 나가는 방식이다.
단점은 행정적 오버헤드가 크다는 것이다. 소규모 프로젝트나 요구사항이 이미 명확한 프로젝트에는 적합하지 않다.
Agile: 변화에 대응하는 방식
1990년대 닷컴 붐이 일어나면서 소프트웨어 개발 환경이 급격히 바뀌었다. 요구사항이 시시각각 바뀌고, 시장 출시 속도가 곧 경쟁력이 되었다.
기존의 무거운 프로세스 모델로는 이 속도를 따라갈 수 없었다. 그래서 더 가볍고 유연한 방법론들이 등장했고, 2001년 이 방법론들의 공통 가치관을 정리한 애자일 선언(Agile Manifesto) 이 발표되었다.
애자일 선언의 핵심 가치는 다음 네 가지다.
- 프로세스와 도구보다 개인과 상호작용
- 포괄적인 문서화보다 동작하는 소프트웨어
- 계약 협상보다 고객 협업
- 계획 준수보다 변화에 대응
오른쪽 항목도 가치 있지만, 왼쪽 항목을 더 중요하게 여긴다는 것이 핵심이다.
XP, Extreme Programming
"좋은 개발 관행을 극단까지 밀어붙인다"는 것이 이름의 유래다.
XP의 주요 실천법은 다음과 같다.
계획(Planning)
- 점진적 계획(Incremental Planning): 요구사항을 사용자 스토리(User Story)로 기록하고, 자원과 우선순위에 따라 릴리스에 배정한다.
- 소규모 릴리스(Small Releases): 비즈니스 가치를 제공하는 최소한의 기능부터 빠르게 배포하고, 이후 지속적으로 추가한다.
설계(Designing)
- 단순 설계(Simple Design): 현재 요구사항을 충족하는 데 필요한 만큼만 설계한다. 미래를 위해 과도하게 설계하지 않는다.
- 리팩토링(Refactoring): 코드를 지속적으로 점검하고 단순화한다.
개발(Developing)
- 테스트 주도 개발(TDD, Test Driven Development): 기능 코드보다 테스트를 먼저 작성한다. 테스트 자체가 명세다.
- 페어 프로그래밍(Pair Programming): 두 명이 한 컴퓨터 앞에서 함께 코딩한다. 한 명은 코드를 작성(Driver)하고, 다른 한 명은 전략적 방향을 검토(Navigator)한다. 생산성과 코드 품질이 동시에 올라간다.
- 집단 소유권(Collective Ownership): 모든 팀원이 코드베이스 어디서나 작업할 수 있다. 특정 코드를 특정 개인만 담당하는 구조를 피한다.
테스팅(Testing)
- 지속적 통합(Continuous Integration): 완성된 작업은 즉시 전체 시스템에 통합되고, 모든 테스트가 통과해야 한다.
- 인수 테스트(Acceptance Testing): 고객 대표가 팀에 상주하며 사용자 스토리의 인수 기준을 직접 검증한다.
지속 가능한 페이스(Sustainable Pace)
- 잦은 야근은 결국 코드 품질과 팀 생산성을 모두 갉아먹는다. XP는 지속 가능한 속도를 유지하는 것을 명시적인 실천법으로 삼는다.
스크럼(Scrum)
스크럼은 보통 2주 단위의 스프린트(Sprint)를 반복하며 개발을 진행한다. 소규모 팀이 공식적인 절차보다는 실질적인 협업에 집중하는 방식이다.
결론: 어떤 모델을 쓰는 게 맞는가?
현실에서는 어느 한 가지 모델을 교과서적으로 따르는 팀이 드물다. 대부분은 여러 모델의 장점을 조합해서 자신의 상황에 맞게 커스터마이징한다.
그렇다면 이 모든 걸 공부하는 이유는 무엇인가?
각 프로세스 모델이 왜 등장했는지, 어떤 문제를 해결하려 했는지를 이해하면, 지금 내가 속한 환경에서 어떤 접근이 더 효과적인지를 스스로 판단할 수 있기 때문이다.
정리하면 다음과 같다.
- 요구사항이 명확하고 변경이 거의 없다 → 폭포수 / V 모델이 유리
- 요구사항이 불확실하고 리스크가 크다 → 나선형 모델이 유리
- 시장 속도가 중요하고 요구사항이 빠르게 변한다 → 애자일(XP, 스크럼)이 유리
어떤 모델이든, 결국 핵심은 두 가지다. 체계적으로 계획하되, 변화에 유연하게 대응하는 것. 이 두 가지 사이의 균형을 어떻게 잡느냐가 좋은 소프트웨어 팀을 만드는 기준이 된다.
출처: 경북대학교 손정주 교수님, "소프트웨어공학" 강의 자료
'CS > Software Engineering' 카테고리의 다른 글
[Software Engineering] Fundamentals of Testing (0) 2026.05.26 [Software Engineering] Use Case (1) 2026.04.12 [Software Engineering] Requirement Engineering (2) 2026.04.12 [Software Engineering] 버전 관리 시스템(VCS): Git 핵심 (1) 2026.04.11 [Software Engineering] Design Pattern: Behavioral Patterns (1) 2026.04.10